Vision-Language-Action (VLA) models have recently enabled robotic manipulation by grounding visual and linguistic cues into actions. However, most VLAs assume the Markov property, relying only on the current observation and thus suffering from temporal myopia that degrades long-horizon coherence. In this work, we view motion as a more compact and informative representation of temporal context and world dynamics, capturing inter-state changes while filtering static pixel-level noise. Building on this idea, we propose HiF-VLA (Hindsight, Insight, and Foresight for VLAs), a unified framework that leverages motion for bidirectional temporal reasoning. HiF-VLA encodes past dynamics through hindsight priors, anticipates future motion via foresight reasoning, and integrates both through a hindsight-modulated joint expert to enable a "think-while-acting" paradigm for long-horizon manipulation. As a result, HiF-VLA surpasses strong baselines on LIBERO-Long and CALVIN ABC-D benchmarks, while incurring negligible additional inference latency. Furthermore, HiF-VLA achieves substantial improvements in real-world long-horizon manipulation tasks, demonstrating its broad effectiveness in practical robotic settings.
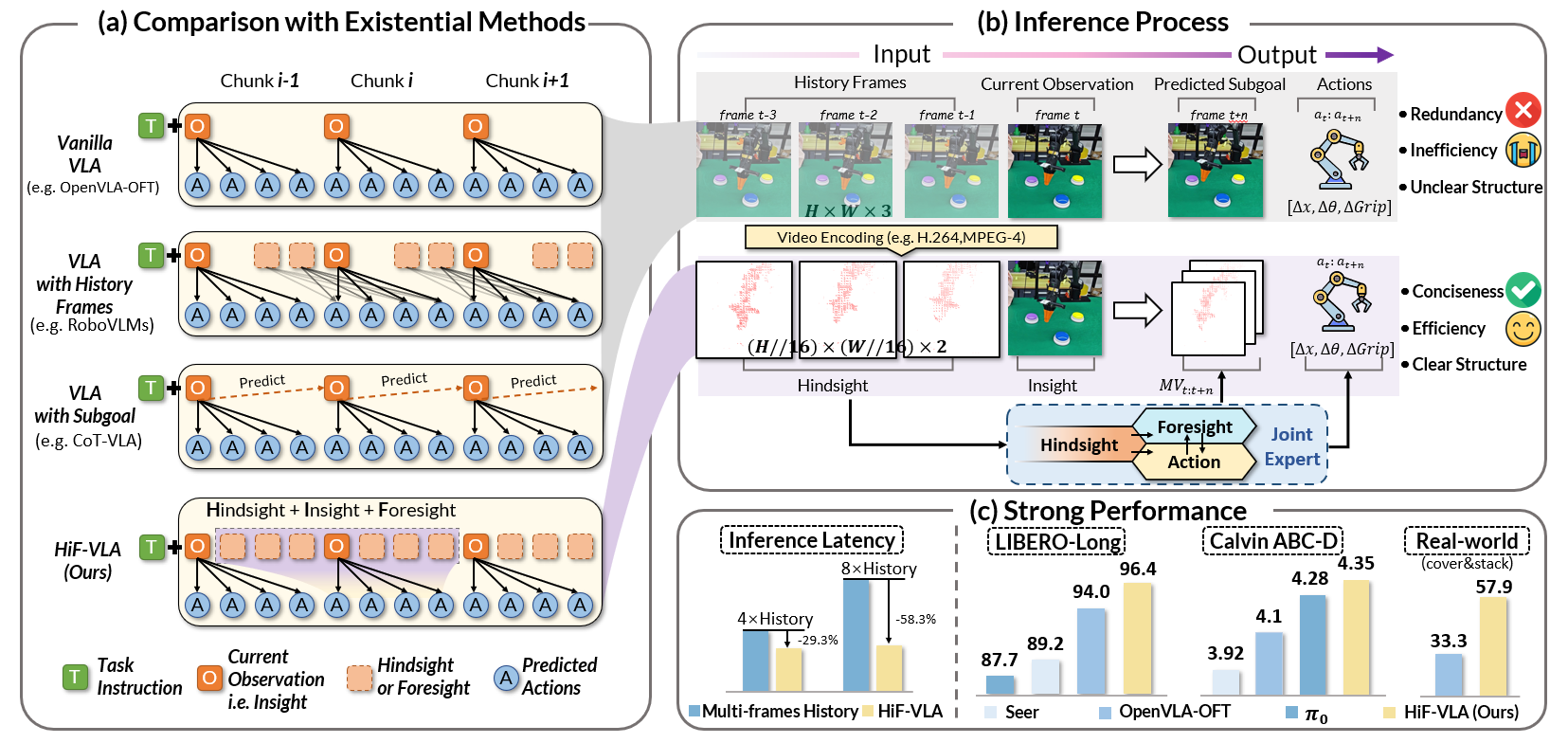
Most existing VLAs implicitly assume a Markov property, predicting actions solely from current observations. This leads to temporal myopia. Common solutions like frame stacking are computationally expensive and introduce massive pixel-level redundancy, obscuring key dynamics.
We argue that motion—rather than raw pixels—is the most precise and compact proxy for history. It captures critical dynamic interactions while explicitly filtering out static visual redundancy.
Furthermore, robust decision-making demands bidirectional temporal reasoning. Motion acts as the natural bridge unifying the past (Hindsight) and the future (Foresight).
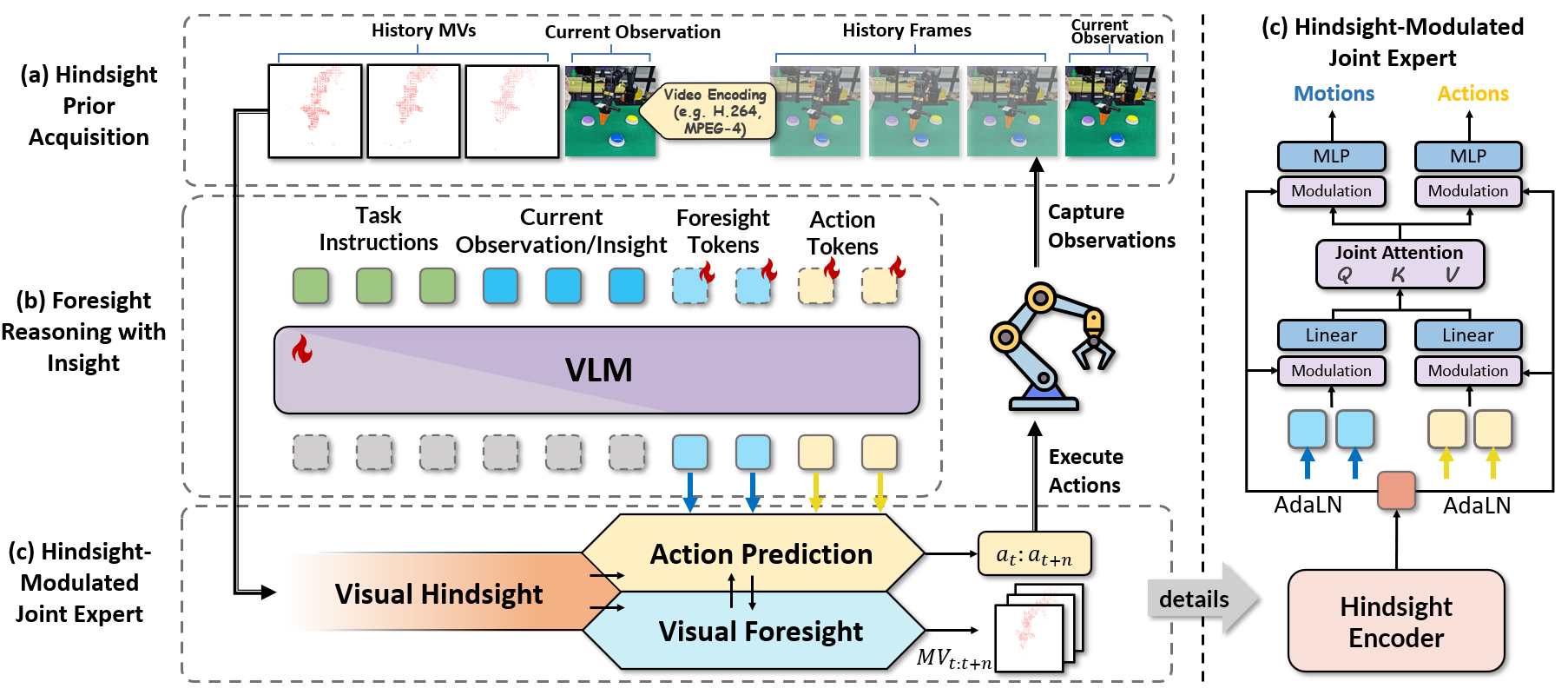
The HiF-VLA Framework. Our approach unifies perception, reasoning, and action through three key stages: (a) Hindsight Prior Acquisition, (b) Foresight Reasoning with Insight, and (c) Hindsight-Modulated Joint Expert.
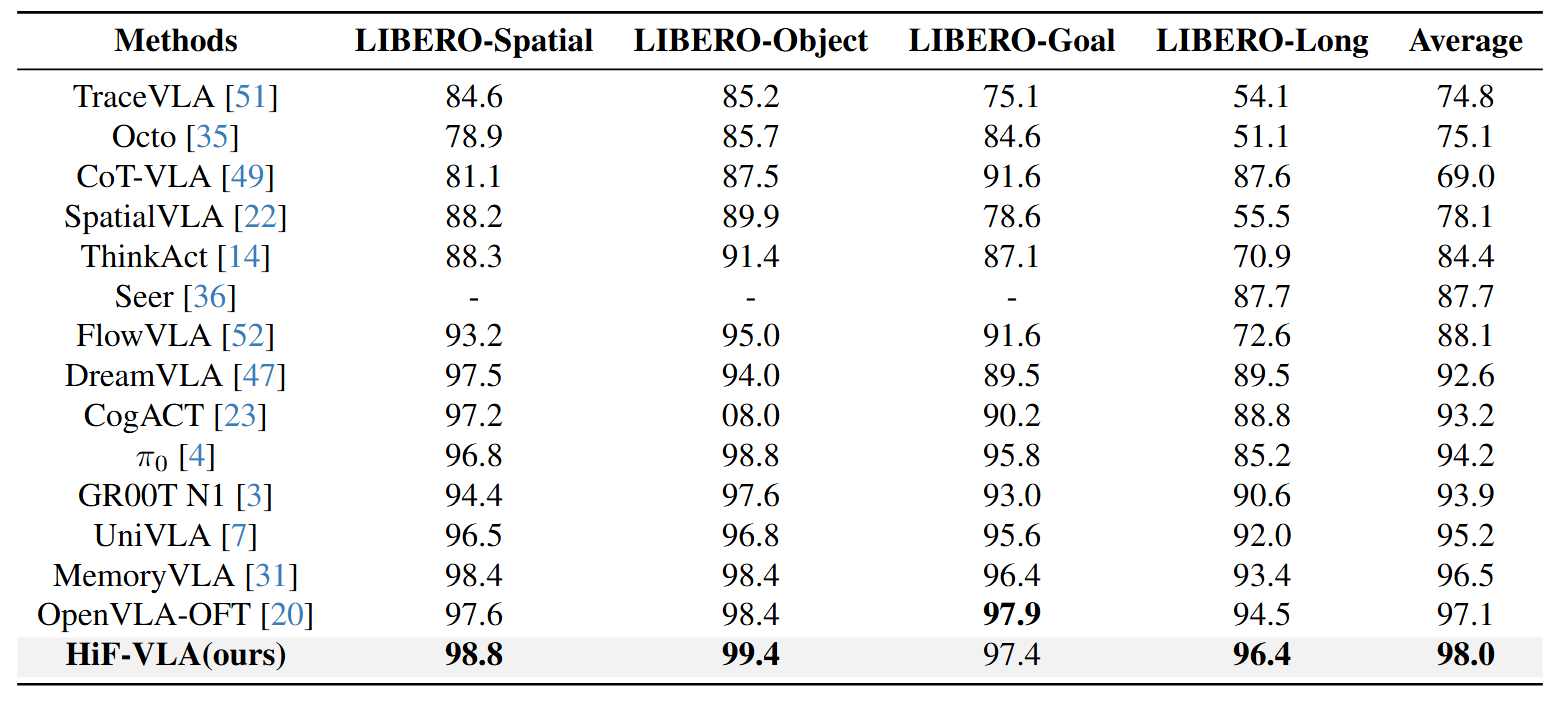
HiF-VLA establishes a new state-of-the-art on the LIBERO benchmark, demonstrating significant gains especially in complex, long-horizon manipulation tasks.
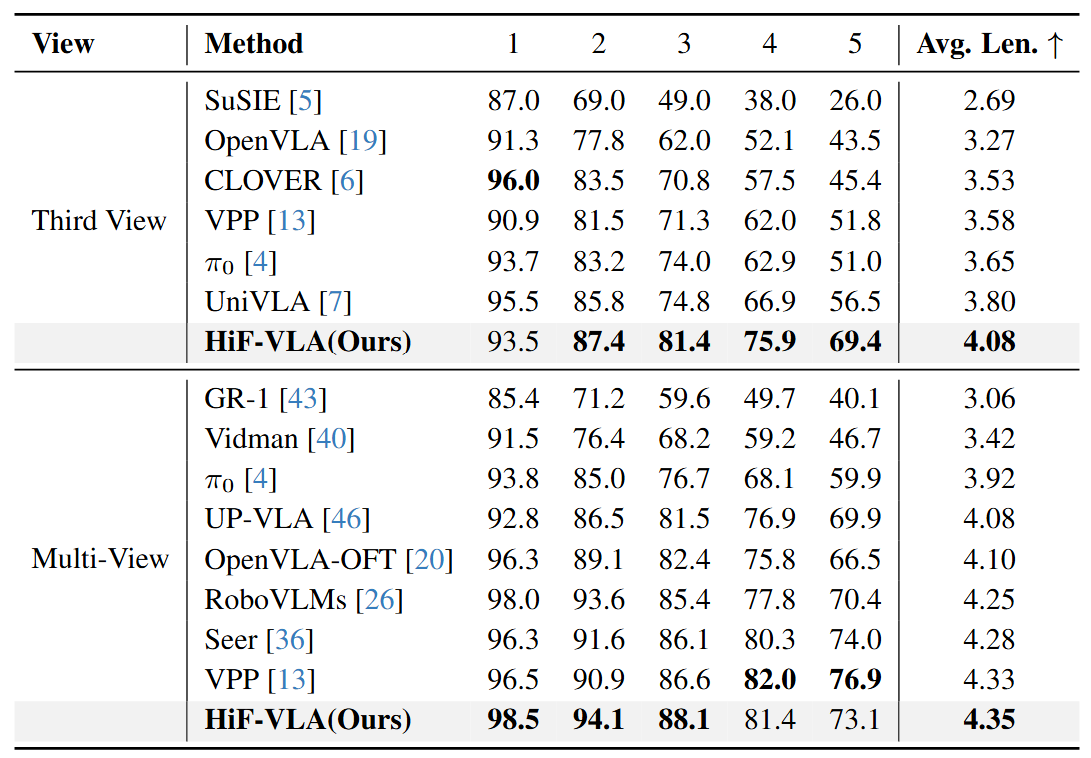
On the Calvin benchmark, our method exhibits superior performance, outperforming existing approaches in average sequence length across both third-view and multi-view settings.
@misc{lin2025hifvlahindsightinsightforesight,
title={HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models},
author={Minghui Lin and Pengxiang Ding and Shu Wang and Zifeng Zhuang and Yang Liu and Xinyang Tong and Wenxuan Song and Shangke Lyu and Siteng Huang and Donglin Wang},
year={2025},
eprint={2512.09928},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2512.09928},
}
 HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models